Research data management toolkit
A toolkit to support you through the entire lifecycle of research data management (RDM). It explains what you should consider and signposts resources from a wide range of websites and organisations.
Why a research data management toolkit?
Today, we create research data in greater volumes than ever before. Therefore, we must ensure that it is safely managed, stored, shared and preserved to act as an evidence base for findings and also so that it can be a valuable resource for future research use.
This toolkit is designed to help the research community discover information on all aspects of research data management – this is currently spread all over the internet and often difficult to reach. It draws together advice and guidance and provides links to best practice in the area.
The research data lifecycle
The RDM toolkit is themed according to the various stages in the research data lifecycle.
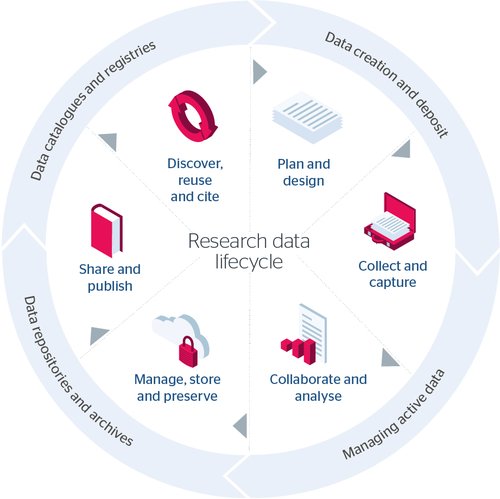
Text description of research data lifecycle infographic
Wheel image showing how the four key stages are linked. These include:
Data creation and deposit
- Plan and design
- Collect and capture
Managing active data
- Collect and capture
- Collaborate and analyse
Data respositories and archives
- Manage, store and preserve
- Share and publish
Data catalogues and registries
- Share and publish
- Discover, reuse and cite
Wheel image showing how the four key stages are linked. These include:
Data creation and deposit
- Plan and design
- Collect and capture
Managing active data
- Collect and capture
- Collaborate and analyse
Data respositories and archives
- Manage, store and preserve
- Share and publish
Data catalogues and registries
- Share and publish
- Discover, reuse and cite
Plan and design
Research data management planning underpins any project. It helps you ensure that data is shared at the right time, with the right people, and after seeking appropriate permissions. It also helps you organise, store and preserve data in a FAIR (Findable, Accessible, Interoperable and Reusable) way.
You should consider research data at the project start, before beginning any practical work. Many research funders now require research data management planning at the grant application stage. As you begin planning, also consider relevant policies, services, and requirements in your organisation. These might not always align with the practices highlighted in this toolkit or in the literature but can override them. For example, your organisation may have certain processes or systems in place that you have to use. A good data management plan reflects the organisational context and leverages it to minimise costs.
This toolkit will help you design your approach to research data management by discussing the main issues in the field and by signposting relevant resources. You should also seek support from research data management specialists within your organisation, who can provide you with tailored advice.
We have prepared a checklist to help you ensure you have a solid RDM plan.
Download the RDM checklist (docx).
Introduction to research data management
Research data management is an important practice for institutions as well as researchers. In essence, managing research data means keeping it well-organised and documented, so that it is easy to share with other researchers and the public. This is an oversimplification, but this toolkit aims to ease your way into the more complex aspects of research data management.
These documents can help you get a sense of the field as a whole and, where they include a bibliography, they might be a useful springboard to get your head round this field.
For the UK context, we recommend reading the Concordat on Open Research Data (pdf) and the report Science as an open enterprise. For an overview of how open data is progressing globally, see the State of Open Data report.
Further reading
- LEARN Toolkit of Best Practice for Research Data Management (pdf)
- UK Data Archive - Research data management
- EMBL-EBI - Bringing data to life - data management for the biomolecular sciences
- Jisc - Directions for Research Data Management in UK Universities (pdf)
- LERU Roadmap for Research Data
- Research data management: a conceptual framework
- LEARN Toolkit of Best Practice for Research Data Management (pdf)
- UK Data Archive - Research data management
- EMBL-EBI - Bringing data to life - data management for the biomolecular sciences
- Jisc - Directions for Research Data Management in UK Universities (pdf)
- LERU Roadmap for Research Data
- Research data management: a conceptual framework
Data management planning
A data management plan is a formal statement describing how you will manage and document data in a research project, and how you will ensure long-term preservation. Researchers should consider data management planning for very good reasons, as this practice:
- Improves efficiency in research
- Ensures information is protected
- Allows results to be checked by others
- Improves exposure via sharing
- Allows you to comply with funders’ policies
Data management plans are increasingly required by research funders. Principal investigators are often expected to submit one at the research proposal stage and maintain it after obtaining funding. The Digital Curation Centre provides examples of data management plans for the most common research funders in the UK.
Data management plans should be clear and concise, proportionate, focused, and structured. You should not approach data management planning rigidly, as projects have different durations, output types, team structures, responsibilities, and more.
Getting help in preparing a research data management plan
The UK-based DMPOnline (and its US counterpart DMPTool) provides a step-by-step wizard to build a data management plan tailored to your needs and compliant with your funder’s requirements. Not everyone in a project will be familiar with all questions in the template, so it is important to have access to project partners and local specialists when needed.
For a checklist of topics to keep in mind when preparing your plan, we recommend the Australian National Data Service's guide to data management plans (pdf) .
Further reading
- Wellcome - How to complete an outputs management plan
- European Research Council (ERC) - Data Management Plan Template (docx)
- University of Sheffield - Examples of RDM plans and templates
- ICPSR - Framework for Creating a Data Management Plan
- European Commission Directorate General for Research and Innovation - Guidelines on FAIR Data Management in Horizon 2020 (pdf)
- LIBER - DMP catalogue
- Jisc - What to keep: A Jisc research data study (pdf)
- Science Europe - A framework for discipline-specific RDM
- Wellcome - How to complete an outputs management plan
- European Research Council (ERC) - Data Management Plan Template (docx)
- University of Sheffield - Examples of RDM plans and templates
- ICPSR - Framework for Creating a Data Management Plan
- European Commission Directorate General for Research and Innovation - Guidelines on FAIR Data Management in Horizon 2020 (pdf)
- LIBER - DMP catalogue
- Jisc - What to keep: A Jisc research data study (pdf)
- Science Europe - A framework for discipline-specific RDM
Policy compliance
When carrying out research, you should ensure you comply with relevant funders’ policies. However, you should not forget your organisation might have policies, too.
The transition to open science started with efforts to support open access to research publications, but the agenda has now expanded to embrace open data. Research funders are starting to require that the results of publicly-funded research and the underlying data be made available along with the publications they accompany.
Policies on research data are sometimes dealt with at national level, although research funders often play a role. Funders normally have widely different policies, based on their remit and the type of data created by researchers in the field. In the UK, RCUK has set out clear expectations that higher education institutions must take responsibility for RDM, preservation and sharing.
Researcher data is not limited to STEM disciplines - your research will likely generate data and, if you receive public funding, you may well be subject to a data management policy.
What do funders want?
The Digital Curation Centre and the University of Bristol curate a list of funders’ requirements, and the latter provides pdf guides on funders’ requirements. For more detailed information on policies, you can refer to the following pages:
- UK Research and Innovation (UKRI)
- Cancer Research UK (CRUK)
- European Commission
- Gates Foundation
- National Institute of Health
- National Institute for Health Research
- Royal Society
- Wellcome Trust
In addition, remember to check your organisation’s internal data management policy. This will be different from funders’ policies, but largely overlapping. You should be aware of what your organisation expects, too – get in touch with your local research data management team (this is likely part of library services or information services) if you have questions about the relationship between organisational and funder policies.
Further reading
European Commission Directorate General for Research and Innovation - Guidelines on FAIR Data Management in Horizon 2020
European Commission Directorate General for Research and Innovation - Guidelines on FAIR Data Management in Horizon 2020
FAIR principles in research data management
FAIR principles ensure that research outputs are findable, accessible, interoperable and reusable. In practice, they enable higher visibility and reuse potential for data.
A research data management plan must consider who will be able to reuse the data, under what conditions, and how. If circumstances change during a project, you can review the data management plan and update it accordingly.
A key concept to improve your data sharing practices is that data should be FAIR:
- Findable: your data should include metadata and a persistent identifier, to make it discoverable.
- Accessible: data and metadata should be retrievable through a free and open communications protocol. Metadata should always be available, even if data is not.
- Interoperable: metadata should use controlled vocabularies, be machine-readable and include references to other metadata. Data should use open formats whenever possible.
- Reusable: metadata should conform to standards for greatest reusability. It should be clear to humans and machines alike. Data should also come with a clear and accessible licence to regulate reuse.
Accessibility does not imply that data should always be open, as access might be constrained due to legitimate concerns around privacy, national security, or commercial interests. In such cases, you should explain why the data is not open and what the conditions for access are.
Responsibilities for making data FAIR are shared between researchers and infrastructure providers (eg online repositories).
What are the benefits of FAIR data?
Making data FAIR benefits all the stakeholders in the research data landscape. You will be able to increase the visibility of your research and the number of citations.
In addition, you will make the research reproducible and aligned with international standards. Researchers and universities can leverage FAIR data to build new partnerships and answer new research questions. The impact of research data can be maximised when data is FAIR. This follows from it being easily and clearly accessible, both technically and legally.
EUDAT developed a useful checklist to help you understand whether your research data management plan complies with the FAIR principles, and how you can improve it.
Further reading
- Nature - The FAIR Guiding Principles for scientific data management and stewardship (introduction)
- Force11 - Guiding Principles for Findable, Accessible, interoperable and re-usable data
- Jisc report - FAIR in practice
- Nature - FAIRsharing as a community approach to standards, repositories and policies (DOI)
- ALLEA - Sustainable and FAIR data sharing in the humanities
- Nature - The FAIR Guiding Principles for scientific data management and stewardship (introduction)
- Force11 - Guiding Principles for Findable, Accessible, interoperable and re-usable data
- Jisc report - FAIR in practice
- Nature - FAIRsharing as a community approach to standards, repositories and policies (DOI)
- ALLEA - Sustainable and FAIR data sharing in the humanities
Costing
Performing research data management is an investment of both time and money. Therefore, costing it appropriately in a research data management plan is essential.
A difficult question is how to account for costs. This is often required in data management plans and should be kept in mind when applying for funding. There are two main approaches to costing:
- Calculating the cost of all data-related activities, including generation, curation, sharing, access, and preservation
- Costing only the activities needed to preserve data and make it shareable. Note that this approach would exclude anything related to the research itself (eg generating data).
The first approach would return a larger figure and document the full costs from data creation to sharing, while the latter would only consider the activities required to manage, document, organise, store, and share data.
The second approach is perhaps a more precise measure of research data management costs, but disentangling research data management activities from research is a complex exercise.
Costing methodologies
Even within these approaches, there are different methodologies in use. In particular, we highlight bottom-up costing and top-down costing (also known as Activity Based Costing (ABC) and Traditional costing, respectively).
The bottom-up approach adopts an activity-based costings framework, which breaks the broad services into detailed activities (for example ingest, access, acquisition, disposal) and identifies the various labour and capital costs associated with each of them. See the CCSDS's reference model for an open archival information system (pdf)
The top-down approach identifies broad research data management services (for example data management planning, data cataloguing and registry services) and the various labour and capital costs associated with them. In both cases, assumptions about data volumes are used to scale up and derive a total cost at the institutional level.
While more accurate costings result from the bottom-up method, it is more resource-intensive and demanding with regard to data collection and monitoring requirements. The cost data for the top-down approach can often be drawn from existing cost data collected by institutions.
The UKRI Common Principles state that “it is appropriate to use public funds to support the management and sharing of publicly-funded research data”. You should check with your funder(s) whether these are going to be met as part of the research grant. The University of Bristol has a helpful list of funder policies.
Getting help to cost your data management activities
To cost research data management you can list all relevant activities and estimate the time and resources each activity needs. The UKDS released a costing tool with a checklist of activities and clear recommendations on expected costs. When costing research data management you should check what your organisation already offers. For example, some research performing organisations have systems in place to store and backup data, which can decrease the cost of research data management, even significantly.
Costing research data management in research performing organisations
Costing is a pressing matter at a higher level, too. Higher education institutions and online repositories deal with data curation and preservation on behalf of researchers and data users. These costs are difficult to analyse because cost models often do not apply to different organisations. To bridge this gap, the Curations Costs Exchange platform was set up to understand and compare the costs of curation and preservation.
Finally, keep in mind that not all organisations are funding digital preservation at the moment. If your organisation wishes to commence such activities, the Digital Preservation Coalition prepared a business case toolkit. In addition, CESSDA released a cost-benefit advocacy toolkit, which outlines how different factors can affect the costs of curation and digital preservation activities.
Research data in arts, humanities and social sciences
The idea that data management does not apply to arts, humanities and social sciences is a little old-fashioned. Researchers in these disciplines frequently collect and analyse both quantitative and qualitative data that must be safely captured, catalogued, stored, shared and protected.
Your research data
In these fields, the concepts of “data” and “evidence” are very nuanced. However, virtually all information you record during your research counts as such. Here are some common (yet not exhaustive) examples of data captured in the arts, humanities and social sciences:
- Focus group notes
- Fieldwork notes
- Finding aids
- Interviews (audio/video) and transcriptions
- Interview coding
- Meeting minutes
- Text corpus/corpora
- Thematic research collections
- Digitised books, paintings and other works of art (eg the Europeana collections).
As a researcher in these disciplines, you will often collect evidence empirically and you may be more likely than other disciplines to collect personally identifiable information with direct identifiers. Make sure you consider both the ethical and the legal requirements that apply to your data when planning for its collection, sharing and long-term preservation.
You can consult the guidance provided by the ICPSR (pdf).
Digital humanities and social sciences
Digital humanities and digital social sciences have risen as interdisciplinary research fields that use information sciences as a research tool in the traditional humanities and social sciences domains. Digital humanities and social sciences use technology to address some research questions more effectively and on a larger scale. This includes two approaches:
- ‘Big data’ digital humanities and social sciences analyse large and interconnected datasets using cutting-edge data processing and interpretation tools and methods.
- ‘Small data’ digital humanities and social sciences use digital tools to perform the analysis and interpretation of smaller and simpler datasets.
If you are planning to embrace digital humanities and social sciences, these articles will help you understand how these methods can contribute to your research and to find examples of existing research projects:
Further reading
Collect and capture
Once a research data management plan is in place and a project has started, attention moves to data collection.
You need to implement the original plan rigorously and make sure that you follow good practice in the field. Methods and equipment for data collection are research-specific and will be detailed in the research proposal. This section discusses how you can organise and document research data and where it should be kept:
- Use the right system to store research data, along with an appropriate backup solution. Your organisation may be able to help with this, but complex projects might need a custom approach
- Document the data you collect by adding metadata. Metadata is information about your data and is one of the most important aspects of research data management. Accurate and well-structured metadata enables others to find your work, contextualise it, reuse it, and cite it
- Think about file formats, naming and folder structure. File formats will affect future compatibility and data reuse. Use a file naming convention and an appropriate folder structure to help locate information
Active data storage and backup
Active data is data that is added as a research project develops. Knowing where to store it, including physical copies, digitised documents, datasets and multimedia files, is important. It might well prevent the failure of your project, as good data storage practices protect you from data loss and enable effective collaborations.
Before making any plans about active data storage, you should check whether your organisation has a preferred approach or has solutions already in place such as networked drives or institution-provided cloud storage. This could reduce costs and help you comply with local research data policies.
Tips for safe data storage
Media fails! You will experience a failure in your lifetime. Whether or not it is catastrophic depends upon steps you take. To store digital information, you can choose CDs/DVDs, hard drives, SSDs, the cloud and other media. Each storage solution presents risks, often related to the long-term reliability of the device, the medium used and, for some projects that span a number of years, the longevity of the software required to access and use the data. Best practice suggests that you should:
- Use at least two types of storage media
- Replace them every two to five years
- Carry out integrity checks based on the principle of fixity
In some cases, you might wish to store laboratory notes throughout a project. The state-of-the-art approach to this is to use electronic research notebooks, which allow you to make notes but also to share, search, protect, and back them up.
There is a growing trend towards using cloud-based dropbox style storage products for storing active data. Whilst undoubtedly convenient, there are some potential drawbacks that need to be considered. For instance, although some products allow a degree of 'roll-back' to previous versions, many don’t. If something is deleted from such a storage space, recovery may be difficult, if not impossible. Similarly, overwriting a file may prevent you from recovering a previous version. Most often, cloud-based storage solutions are not a substitute for a correctly configured and instigated backup procedure.
This might seem like a lot of work for just deciding where to store your everyday work, but data loss horror stories are a sobering reminder of the consequences of taking data storage and backup lightly!
Why back up research data?
The best way to keep your research data safe is to consistently back it up. Backups can protect your data from hardware failures, thefts, software faults and more. You will need to think about:
- What to backup
- What format to use
- How many copies to keep
- How long to keep them for
- How frequently you back-up
- How often you take a snapshot of the data to preserve an “instance in time”
It is also important to assign responsibilities for data storage and backup: always make sure that someone in the team knows it is their job to check that data exists and is safeguarded.
Perhaps most important of all is to test your backup procedures to make sure the data is actually being backed up and that it is recoverable should a disaster happen. Your organisation might have a strategy in place to manage backups, so check with relevant IT specialists. Alternatively, there are tools that can help you back up research data more efficiently via automated workflows. Note that backup should not be confused with data preservation!
Backing up personally identifiable information
When backing up your research, you need to think about how to protect personally identifiable information (such as racial or ethnic origin, political opinions, religious beliefs). Try to create as few copies of personal data as possible, which reduces security concerns and makes it easier to destroy the backed-up data when the project ends.
The storage location of personally identifiable information is equally important. It is also paramount that you consider the security of such information, who might gain access, how they might gain access and the consequences if this should happen.
Further reading
- Nature - 11 ways to avert a data-storage disaster
- OCLC- Building Blocks: Laying the Foundation for a Research Data Management Program (pdf)
- Community Owned digital Preservation Tool Registry (COPTR)
- Labtrove - electronic lab notebook
- REDCap (Research Electronic Data Capture)
- Matters in Media Art - Design your storage
- A comparison of research data management platforms: architecture, flexible metadata and interoperability
- Nature - 11 ways to avert a data-storage disaster
- OCLC- Building Blocks: Laying the Foundation for a Research Data Management Program (pdf)
- Community Owned digital Preservation Tool Registry (COPTR)
- Labtrove - electronic lab notebook
- REDCap (Research Electronic Data Capture)
- Matters in Media Art - Design your storage
- A comparison of research data management platforms: architecture, flexible metadata and interoperability
Metadata - documenting research data
Metadata is a description of your research data. It helps others interpret and reuse your findings by providing information and insights into your work and methodology.
When you have a conversation, context drives understanding. The same goes for data: data without context is either unclear or unintelligible, as you won’t know how it came to exist, where, and why.
The context of your data is called metadata, which means “data describing other data”. When you provide metadata along with your research, other people can reuse it. Your data becomes more easily discoverable and the potential for citations increases. Note that good metadata can also help its original creator should they wish to return to it in the future.
Ideally, you should prepare metadata at study level and at data level (for the stored datasets). The former should include information on:
- The aims of your project
- The methods used to collect data
- The contents of your data
- The folder structure and file naming conventions
- The data processing techniques used
- The modifications made to the initial data throughout the project
- Data validation and other quality assurance processes
- Roles and responsibilities within the project
- Details on identifiers, licensing, and sensitive information.
Metadata at the data level is a completely different story, as disciplinary differences and different standards exist (more on this in the section below).
Creating metadata for your research results
In practice, creating metadata means filling in some fields with information about your work. However, finding out which fields you should use and when can be a daunting task. The two options to create metadata for your work are using templates or using standards.
Templates are most often simplified versions of standards and you will just have to look at what other people have done and follow their example.
Standards are more complicated and require technical understanding, but maximise reach and discoverability. If you wish to use a metadata standard, this list of standards developed by the Research Data Alliance can help you pick one that is appropriate to your field. Another good starting point is the FAIRsharing list of standards. If in doubt, you can use generic schemas such as Dublin Core.
As a side note, mainstream software for quantitative and qualitative analyses support the addition of metadata. This includes, SPSS, MS Access, or MS Excel for quantitative studies or NVivo for qualitative ones.
Further reading
- COPTR - Metadata tools
- Research Data Management Service Group - Guide to writing "readme" style metadata
- A Comparative Study of Platforms for Research Data Management: Interoperability, Metadata Capabilities and Integration Potential
- COPTR - Metadata tools
- Research Data Management Service Group - Guide to writing "readme" style metadata
- A Comparative Study of Platforms for Research Data Management: Interoperability, Metadata Capabilities and Integration Potential
File management and formats
File management includes folder structures and naming conventions, plus the choice of appropriate formats.
Creating a folder hierarchy
With regards to folder structures, a good way to go about organising your research data is to create a hierarchy of folders. As an example, you could use a folder for each project, with two subfolders:
- 'Data', to store your research data, including images, databases, media, etc.
- 'Documentation', to store all relevant project documents, including, eg methodology and consent forms
The more complex the project, the more detailed your folder structure can be. If you are working alone or in a small team, you might wish to use just a handful of subfolders.
However, if you work on a large project you could create a range of subfolders to suit the team’s needs. As an example, under 'Data', you might create a subfolder for each data type, such as 'Databases', 'Images', and 'Sounds'. Similarly, under 'Documentation' you might create a subfolder for each category of document, such as 'Methodology', 'Consent forms', and 'Information sheets'.
Naming your files to support collaboration
When it comes to file naming, we recommend using simple but meaningful names. Best practice includes the following:
- Capital letters should be used to delimit words in the place of spaces or underscores
- File names and paths should avoid unnecessary repetition and redundancy
- Numbers should always include at least two digits (ie 01 to 09 instead of 1 to 9)
Naming will follow a convention chosen by you and other project members. For instance, you may decide that 'InterviewTra07JD20180214' means 'Interview Transcript 7, written by John Doe, on 14/02/2018'. You will need to describe such conventions as part of your study’s metadata.
Choosing the right file format
Finally, choosing appropriate file formats is key to ensuring data is reusable, as some formats become obsolete in time and may make your research inaccessible. You can use whatever software or format is convenient during your research, but when sharing the data you should follow best practice and ensure future reusability of your work. The US Library of Congress maintains a recommended formats statement, which we invite you to consult. This lists a series of file formats in order of preference by output type, including recommended metadata fields.
When saving research data for sharing, you might need to convert your working files. If you do so, always ensure that the conversion was successful and that no errors appear (eg missing values, wrong characters, text formatting, resolution, etc.).
Further reading
- Australian National Data Service (ANDS) - File formats (pdf)
- KU Libraries Data Management Basics Learning Module: Directory Structures
- KU Libraries Data Management Basics Learning Module: File Naming
- Australian National Data Service (ANDS) - File formats (pdf)
- KU Libraries Data Management Basics Learning Module: Directory Structures
- KU Libraries Data Management Basics Learning Module: File Naming
Collaborate and analyse
Research is often conducted in teams, and these can operate nationally or even internationally. Establishing (and documenting) appropriate data management processes before project start is key. This includes setting up a data management resources library, defining roles and responsibilities, and tracking data carefully. In collaborative projects, file sharing takes a front seat and complicates how you deal with active data storage, too.
Assigning roles and responsibilities appropriately during a project is also important. This includes, eg putting someone in charge of a dataset and its maintenance. They will have to document the methods of analysis and the conventions used, so as to enable collaborators to reuse the data smoothly.
We believe that this lifecycle step makes our journey through research data management clearer. You can now start seeing how good data management planning leads to successful collaborations and analysis: the more you think about research data management initially, the smoother your pathway to impact will be.
Collaborative research
If you work in a team, we recommend you read this page carefully. Here, we highlight solutions and considerations specific to teamwork, which differ from non-collaborative projects. Broadly speaking, there are two possibilities when collaborating in a project:
- Your team is located within your organisation
- Your team includes external collaborators (eg researchers at other universities, commercial partners, etc)
Approaches to data sharing in collaborative projects
The first option above is simpler, as the organisation can provide a research data management infrastructure. For dispersed teams, the project leader(s) will have to decide whether to use:
- A single participating organisation’s data management infrastructure, or
- A custom shared data management infrastructure
The benefit of using an existing infrastructure, including methods and standards, is that you will be able to use existing documentation to describe the approach used. However, some project members might not be familiar with your choice or prefer a different one.
Custom shared spaces include popular services such as Dropbox, Google Drive, OneDrive or Box and advanced options such FTP servers, virtual research environments, content management systems (eg SharePoint), and more. Note that some institutions offer accounts with the above cloud service providers. If available, we recommend you use these rather than a personal account with the same providers, as institutional subscriptions would typically include more advanced functionality and more storage space.
Online repositories are viable as well, although they tend to be better for long-term storage. When using custom solutions, remember to document your approach to research data management. While an organisation would most often have guidelines, a team spanning several ones or even different countries will need shared guidance that is easy to consult.
Platforms and tools to support collaborative projects include:
Security in collaborative projects
When choosing collaborative platforms, you should think carefully about data security. If security is a concern (eg if you collect personally identifiable information, we recommend using encrypted storage areas as opposed to cloud-based services like Dropbox and Google Drive. Should you need to set up encrypted storage areas, we recommend you get in touch with local IT specialists to see what is available in your organisation.
You should also remember that the system used for day-to-day file storage must be different from the one used for backups: the former can be online and in the cloud, while the latter should preferably use offline media.
In addition, international collaborators might be subject to different policy and regulatory requirements. Therefore, you should ensure that data security considerations take into account all the appropriate policy landscapes and that personally identifiable information is protected. Particularly, you should be careful when transferring data beyond national boundaries (pdf) .
File versioning
Ensure that all team members are up to speed with file versioning too. Cloud-based systems commonly include file versioning in their paid-for editions, but this can also be done manually by team members. There is no right or wrong approach here, as long as one approach is used consistently and is well documented.
As an example, you could add a version number at the end of a filename, such as “InterviewTra07JD20180214v2” - meaning ”Interview Transcript 7, written by John Doe, on 14/02/2018, version 2”.
Further reading
- Jisc - Increase your research competitiveness through collaboration
- Research Data Alliance - Principles and best practices in data versioning for all data sets big and small (doc)
- UK Data Service - Managing and sharing research data
- Software Sustainability Institute - Top tips for research software
- The Royal Society - A snapshot of UK research infrastructures (pdf)
- Jisc - Increase your research competitiveness through collaboration
- Research Data Alliance - Principles and best practices in data versioning for all data sets big and small (doc)
- UK Data Service - Managing and sharing research data
- Software Sustainability Institute - Top tips for research software
- The Royal Society - A snapshot of UK research infrastructures (pdf)
Visualisations
A picture (or chart) is worth a thousand words. They help researchers disseminate their findings more effectively and to a wider audience, although careful thought is needed to design them.
Creating visualisations used to be a niche activity, but has gained importance as a tool to increase dissemination and impact. In simple terms, a visualisation is a chart or figure that represents information graphically. They're a researcher’s best friend as they help communicate data succinctly and convey ideas effectively.
When using visualisation to communicate research, your goal is to strengthen and simplify the main message of your research for your audience. You can pilot your ideas with colleagues, as they will spot issues and you will be able to address them. Thinking about colours, formatting and presentation is essential - design professionals can help.
Visualisations as an investigation tool
Visualisations are also helpful to understand data, as they allow you to discover patterns that aren’t immediately evident. In this case, you would be the audience for the visualisation, so no design considerations are needed. You can go into as much detail as required, and plot the most obscure relationships you might think of.
The main challenge is when you wish to both understand data and to communicate it. Think, for example, of a team meeting where you need to show data to receive feedback or guidance. You will have to consider how to represent enough detail to allow people to comment on your work but also little enough to make your point clearly.
Approaches to creating visualisations
Creating powerful visualisations can be difficult. In a simple scenario, you might create a static visualisation for, eg a slideshow or a poster. You can also use interactive visualisations, where users can play with the data, especially as a digital resource embedded in a webpage. Interactive visualisations are more complex but tools such as tableau public and Google Charts can be helpful. Remember to ensure that data is not stored in unsafe locations and that sensitive information is not exposed when using online tools.
In conclusion, you should keep in mind that data visualisation is an art and a science at the same time. While creativity is important, clarity is, too. If you are missing either the technical or graphical skills required, get in touch with support staff in your organisation.
Further reading
- Software Sustainability Institute - Top tips on software for data visualisation
- Software Sustainability Institute - Top tips on software for data visualisation
Manage, store and preserve
The efforts mentioned in the previous lifecycle steps aren’t one-off exercises. Every decision you make before starting a project has clear repercussions on its evolution. The storage location chosen affects file management and formats and this will affect preservation. As you carry out your research, you need to routinely think about data management, storage, and preservation - although the first two are a priority earlier on in the process.
Throughout the life of a project, you might realise that your approach to research data management has become outdated or unfit for purpose. If so, you can make changes to the original data management plan. However, you should keep in mind that any decision will affect all subsequent steps so these should be revisited too.
Here, we discuss how you can protect research data during a project. This includes technical considerations (ie security, preservation) and legal ones (ie data protection regulation). We also shed light on the topic of managing software created within a research project. Although this is often not regarded as data, it actually is. Researchers sometimes treat software as a means to an end, yet it is an essential part of the research process and should be documented and shared. In addition, note that the availability of the computer code behind a study (if any) is an enabler of research reproducibility.
Many of the issues discussed in this section are relevant for both active data and archival datasets. The former is data that is added as a research project develops, while the latter are the final outputs underpinning your work.
Preservation
Data preservation aims to keep both content (data) and context (metadata) safe for future reuse. Preservation is made significantly easier when considered in your data management planning process.
What is preservation? Putting your data on a spare USB stick is not preservation. Backup is not preservation. Putting the data in a repository is not preservation.
Digital preservation includes a series of activities aimed to ensure continued access to digital materials. This practice is defined very broadly and deals with all the actions needed to maintain access to data regardless of media failure or technological/organisational change. Preservation applies to all data, including “born-digital” material and the products of digitisation processes (as defined by the Digital Preservation Coalition).
Why preserve?
In short, credibility, reproducibility and mandate.
Funders have begun to mandate that the data underpinning published research that they have funded is made freely available for other researchers to use (note that this is not the same as ‘open data’ – some data covered by this mandate may only be made available under strictly controlled conditions). The mandate is often further interpreted as ‘keep available and usable’. There is little value in keeping data if it cannot be used. Note that some institutions also require data to be retained for fixed periods of time. Check with yours to find out whether this is the case.
Preservation systems are designed with future usability in mind.
They make multiple copies of preserved data, automate checks to make sure data has not been changed or damaged and convert data in old formats to newer ones so it can be opened with new technology. These systems are also sometimes designed to make metadata discoverable to other researchers and users. Where appropriate, preservation systems may also provide emulation services.
Preserving the data and/or computer code underpinning research also provides a degree of protection for the reputation of a researcher and/or institution. This practice allows others to reproduce and validate results – in some cases, many years after the original project.
Keeping content and context safe
This practice is important because both content and context need protection (and research funders know it). When data and/or computer code are preserved with appropriate metadata, content and context are safely stored and can be reused in the future. If either is lost, data immediately becomes at risk. Sometimes, just a change in file formats will be enough to make your research unusable. This is why thinking about file management and formats is so important! The above, however, does not mean that you should preserve everything you produce. As part of a project, you should select data for preservation and delete what does not need sharing. (See Digital Curation Centre's guide Five steps to decide what data to keep (pdf))
Digitally endangered species
The Digital Preservation Coalition maintains a list (Bit List) of digitally endangered species, including the types of data the community believes are at risk. Among these, unpublished research outputs are classified as critically endangered – which is a call to action for researchers to better engage with data management. In the Bit List, we recommend you also look at the aggravating conditions which may make data loss more likely – in the case of unpublished research outputs, these include, among others, single copies of a file, dependence on devices and dependence on obsolete formats or processes.
PhD data is also considered at risk because there is no widespread approach to its preservation. Some higher education institutions mandate PhD archiving in their regulations, which we encourage as good practice.
Software and hardware preservation
Some data is produced by bespoke hardware and/or software, often producing bespoke file formats. In some instances, the same bespoke system may be needed to read and analyse the data in the future. If this is the case, and there is no alternative, it may be necessary to preserve the software and even the hardware (or an emulation of the hardware) in order to keep the data usable. This is not a trivial task and considerable effort is being put into making better software in the first place and preserving what has already been used.
Preservation for research data managers and IT specialists
Preservation often relies on the IT infrastructure of research performing organisations. Tool registries are available to choose an appropriate approach to this. Well-known systems include:
Should you need to pick a preservation solution, compare them carefully to ensure your choice is appropriate for your objectives.
These systems are generally designed to undertake a number of standard tasks to keep the data safe including:
- Identifying the file type and, if necessary, converting the file to what has been defined in local policy as the ‘Standard’ for that file type (‘Normalise’)
- Creating an archival copy (or copies) and a display copy of the data
- Creating a checksum for the archival copy and regularly performing checks to make sure there is no deterioration and the data is an authentic copy of the originally-submitted record (fixity checks to check for bit-rot)
- Performing file migrations to alternative file types as old formats become obsolete and documenting the characteristics of this migration so that its impact can be understood
- Exposing the data to external display systems where appropriate
- Exposing the metadata to external systems where appropriate
Further reading
- Arkivum - Digital preservation – A how-to guide for beginners (pdf)
- The Keepers Registry
- The Turing Way
- Community Owned digital Preservation Tool Registry (COPTR)
- Digital Preservation Coalition - DPC Rapid Assessment Model
- Digital Preservation Coalition - Executive Guide on Digital Preservation
- Digital Preservation Coalition - Preservation with PDF/A (2nd Edition) (pdf)
- National Digital Stewardship Alliance (NDSA) - Levels of Digital Preservation
- International Household Survey Network (IHSN) - Principles and Good Practice for Preserving Data (pdf)
- Arkivum - Digital preservation – A how-to guide for beginners (pdf)
- The Keepers Registry
- The Turing Way
- Community Owned digital Preservation Tool Registry (COPTR)
- Digital Preservation Coalition - DPC Rapid Assessment Model
- Digital Preservation Coalition - Executive Guide on Digital Preservation
- Digital Preservation Coalition - Preservation with PDF/A (2nd Edition) (pdf)
- National Digital Stewardship Alliance (NDSA) - Levels of Digital Preservation
- International Household Survey Network (IHSN) - Principles and Good Practice for Preserving Data (pdf)
Security
You must ensure that only authorised people can access, copy or edit your research data. Doing so should mean that data will be safe from unauthorised use and personally identifiable information will be seen only by authorised people. Remember that you are legally responsible for protecting personally identifiable information, when present – in these cases, security becomes a requirement rather than a choice.
When does security matter?
Data security includes a series of practical measures to protect yourself and the safety and privacy of data subjects (if any are involved) in worst case scenarios. Think, for example, of the following:
- Someone could accidentally delete your research data
- Commercially-confidential data could be leaked outside of your organisation
- Hackers could get hold of your data
- Personally identifiable information could be exposed
Many other similar scenarios exist and we are sure you wish to avoid them. In fairness, it is usually not too complex to set up security measures for a research project.
Data security in practice
We highly recommend the following practices when you manage research data:
- Digital access control: only trusted colleagues should have 'write' access to important files and directories. All operating systems and most software let you control access levels and permissions for each user
- System level precautions: systems used to store and manage data need to be kept secure through a combination of regular patching and security audit. In this day and age, it is unusual for systems not to be connected to a network: these connections must be kept secure through the appropriate use of firewalls and access control technology. For particularly sensitive information, you could consider data safe havens, secure file transfer networks such as Safe Share or even storing the data on a totally isolated machine
- Physical access control: you should ensure that only trusted people can enter the building/area where you hold data
- Passwords: you should have a strong password controlling access to your computer and any device used in your research. Software to manage passwords may help where you have many of them. CESSDA assembled a few suggestions on password security
- Encrypted storage and files: it is best practice to encrypt your hard drive, which can be done natively on Windows and Apple systems. You can also decide to encrypt single files, which we recommend when using personal data. When encrypting a file, make sure you never lose the encryption key! As an example, mainstream software such as the Microsoft Office suite allows you to encrypt files with a password when saving
- Secure file erasing: when you dispose of sensitive data, you should make sure it is fully removed from your hard drive (pressing the delete key to send it to the bin is insufficient). You can achieve this by physically destroying storage devices (often too extreme), or by using software tools. Data stored in the cloud poses another set of problems – it can be difficult to satisfy yourself that data has been completely destroyed
Further reading
Data protection
Data protection deals with all information that allows you to identify a person. There are specific rules to follow and serious fines in the case of non-compliance.
Personally identifiable information, personal data, or sensitive data all refer to data that allow you to identify a person. Data protection law recognises the protection of natural persons in relation to the processing of personal data as a fundamental right. When you carry out research involving people, informed consent and protecting your participants are crucial.
The ethical review process
The research process is hardwired to achieve the above. Before you even start carrying out the research, an ethical review process is usually required – this is meant to help you think about the ethical issues involved in your work. Most research performing organisations have their own research ethics committee to review your planned research. Note that compliance with data protection law is not always monitored during the ethical review process. In these cases, you should ensure you follow the appropriate local approach to ensure your planned research is compliant.
When ethical review is not mandated, CESSDA recommend that you still perform a self-assessment. This will help you appraise your approach and ensure it is safe and scientifically robust.
Collecting data from human participants
After obtaining ethical approval, you can start your research. Collecting data from human participants is subject to their informed consent and the safest approach to this is seeking written consent via a form. This should explain what participation entails, how results will be disseminated and the impact of the project on participants. You must ensure that participants know that they have full freedom of choice. This information should be stored and linked to the published research and data for possible future review. Obviously, by its very nature, consent information is personally identifiable information and should not be available openly. When a consent form is not a viable option, there are several other approaches to obtaining informed consent, as outlined by the UK Data Service.
Your organisation and you are responsible for protecting participants’ data at every stage of the research: collection, processing and storage.
Data reuse
One of the tensions between data protection and data sharing relates to the reuse of personally identifiable information post-project. In some cases, researchers may plan work that is radically different from that for which consent was originally given. If possible, any informed consent should make provision for future research.
Guidance on data protection
For more detailed information on data protection, see the self-assessment toolkit by The Information Commissioner’s Office.
Protecting personally identifiable information
Personally identifiable information should be protected. This refers to any information that can be used to identify an individual. Anyone processing such information must follow strict legal guidelines. Managing and sharing research data concerning individuals must therefore be understood in this legal context and appropriate safeguards must be put in place.
There is stronger legal protection for data revealing an individual’s:
- Racial or ethnic origin
- Political opinions
- Religious or philosophical beliefs
- Trade union membership
- Genetic data
- Biometric data
- Health
- Sex life or sexual orientation
Types of personally identifiable information
There are different types of personally identifiable information:
- Direct identifiers: information that, on its own, allows you to identify an individual. This includes names, email addresses including one’s name, fingerprints, facial photos, etc. This information presents a high risk.
- Strong indirect identifiers: information that allows you to identify an individual through minimal effort. This includes postal addresses, telephone numbers, email addresses not including one’s name, URL of personal pages, etc. This information presents a moderate risk.
- Indirect identifiers: information that allows you to identify an individual when linked with other available information. This includes background information on people, such as age, location, gender and job title. This information presents a low risk.
You should address indirect identifiers as thoroughly as you would the direct ones.
Anonymising research data
A key approach to protecting personally identifiable information in research data is anonymisation, ie the irreversible removal and deletion of personal identifiers. As a starting point, you should know whether you are performing quantitative or qualitative research. In the former case, anonymisation is slightly simpler, because sometimes all you have to do is delete direct identifiers.
If your dataset is more complex (eg it contains free text), you will have to be more thorough and resort to ad-hoc anonymisation techniques. If you are undertaking qualitative research, anonymisation is far more complicated. It requires a much higher extent of personal judgement and you should follow the best practices highlighted by the UK Data Service.
When anonymising data, it is good practice to consider how and why your data could be linked to other datasets and to take steps to prevent such linking from being possible.
Protection solutions
There are software solutions available for secure bioscience research collaboration. One such solution is DataSHIELD which enables the remote and non-disclosive analysis of personally identifiable information.
Encryption is an approach favoured by some for data security purposes. However, this is not without its own problems, particularly in relation to real-time access and storage/recovery of encryption keys. Key Escrow – the storage of a key by a trusted third party – is a potential solution to key loss, but is not yet widely adopted in the research community and has drawbacks of its own.
Further reading
- Finnish Social Science Data Archive - Anonymisation and personal data
- Open AIRE - How to deal with sensitive data
- LSE - Social media, personal data and research guidance (pdf)
- Finnish Social Science Data Archive - Anonymisation and personal data
- Open AIRE - How to deal with sensitive data
- LSE - Social media, personal data and research guidance (pdf)
Software
Computer code (or software) is a series of instructions written in human-readable language, usually stored in a text file. In the DPC's list of digitally endangered species, research software is classified as critically endangered. It is easy to understand why: software is often considered as a means to an end rather than as part of the research. Yet software too can be a research output and, as such, it should be managed, curated and preserved.
What computer code should be saved?
Not all code written within a project is worthy of preservation, so keep in mind what software is worth keeping or sharing with other researchers. A few questions you can ask yourself in this respect include:
- Is there motivation for preserving the software?
- Do the predicted benefit(s) exceed the predicted cost(s)?
- Are the necessary capability and capacity available?
If your computer code is on a GitHub public repository, the Software Heritage archive takes care of saving it automatically. On their website, you can check if they have already saved your work.
Dealing with computer code during a research project
When planning and conducting research using software, consider the following:
- Treat computer code like any other output of your research. It should be part of your research data management plan or have a tailored management plan.
- Prepare documentation and metadata for your computer code. This includes not only inline comments, but also dependencies and their versions. Documentation should be clear enough for others to replicate the features of your code.
- Share your computer code like you would any other research output. You can share it via a repository (eg GitHub) or in a journal. We highlight the Journal of Open Research Software (JORS, Open Access) by the Software Sustainability Institute, but also their list of suitable alternatives by field. Alternatively, the Code Ocean platform provides researchers with a way to share and run the code they publish along with data and articles.
- Computer code should have a URL or a DOI (digital object identifier). Always include these when citing the code, including information on the version you used. Note that code deposited on Code Ocean receives a DOI. Similarly, it is possible to obtain a DOI for computer code on GitHub using Zenodo.
- Apply a suitable licence. Computer code is slightly different from research data, so appropriate licences exist.
Since software is a complex field, many of its features fall outside the scope of this toolkit. However, in 2018, the Software Sustainability Institute developed a set of complementary guides covering the main aspects of depositing software into digital repositories.
Further reading
- Sustainability Institute - How does software fit into EPSRC’s research data policy?
- Software Sustainability Institute - How to cite and describe software
- The Internet Archive Software Collection
- Software Carpentry - Data management (video lecture)
- nature neuroscience - Toward standard practices for sharing computer code and programs in neuroscience
- Open Working - Workshop Report: Software Reproducibility – How to put it into practice?
- Software Sustainability Institute - Digital preservation and curation - the danger of overlooking software
- Software Sustainability Institute - Top tips
- Sustainability Institute - How does software fit into EPSRC’s research data policy?
- Software Sustainability Institute - How to cite and describe software
- The Internet Archive Software Collection
- Software Carpentry - Data management (video lecture)
- nature neuroscience - Toward standard practices for sharing computer code and programs in neuroscience
- Open Working - Workshop Report: Software Reproducibility – How to put it into practice?
- Software Sustainability Institute - Digital preservation and curation - the danger of overlooking software
- Software Sustainability Institute - Top tips
Share and publish
No matter your field, we recommend that you share your research data. There are many ways you can achieve this. You can share data informally during a project (eg using emails or file sharing services); or you can share data formally at project end or at certain milestones via:
- Data repositories
- Data journals
- Supplementary material to publications.
Sharing and publishing data means that your peers will be able to discover your work more easily. Your data can be citable just like a publication, thanks to persistent identifiers. Moreover, you will enable others to replicate and validate your findings.
If you followed the previous steps carefully, sharing data will be easy. When depositing your data, you will need tidy files, in the right format and with appropriate documentation and metadata. If you haven’t done this in a structured way, odds are that gathering this information will be burdensome.
This is the stage where you have to consider what licence you want to apply to your data. This is essential, as picking the wrong licence might lead to your work being unusable.
In some cases you will not be allowed to share research data because of pre-existing terms and conditions or other legal obligations (eg concerns about national security, or commercial interests). If this is the case, this lifecycle step may not apply to your research.
It should be noted that publishing data is a complex undertaking, as it involves disciplinary norms, technical infrastructure, training and more – the Open Data Institute (ODI) released a report providing useful insights and recommendations for data publishers.
Intellectual property and copyright
Whenever you create something, you automatically receive certain intellectual property rights. Therefore, to enable others to reuse your work, you have to choose an appropriate licence.
Whenever you create something, you automatically receive certain intellectual property rights. This applies to data as well as paintings, books, or music. Intellectual property is what gives the owner control over how their work is used, modified, shared, or licensed.
Copyright is an intellectual property right that is assigned to an author when creating content. It effectively makes research outputs (eg tables, reports, computer code) count as literary works from a legal viewpoint and it has a pivotal role in the sharing and reuse of research data.
Key information on copyright
Here are a few things you should know about copyright:
- The creator(s) of research data automatically get copyright when the work exists in a recorded form
- When you collaborate with others, copyright is shared between the authors or their organisations
- If you create work during employment, your employer is legally the copyright holder. Some employers such as universities sometimes give copyright back to authors, but you should check whether this is your case. If you are a research student (eg a PhD student), your situation might differ – you should refer to your contract to find out which rules apply
- If you deal with recorded or transcribed interviews you hold the copyright on these. Yet interviewees are considered as authors of their recorded words. If you wish to share these, you should seek a copyright transfer from the interviewees
- To transfer copyright, you need a written document called an assignment
- The concept of fair dealing normally allows you to reproduce data for non-commercial teaching or research purposes. However, be careful about your actions as there is no statutory definition of fair dealing and each case is evaluated qualitatively. Note that this is a national UK law and alternatives exist in other countries (eg the fair use doctrine in the United States)
- Databases can benefit from two forms of protection: copyright deals with the content of the database, while database right deals with its structure. Note that database right only applies under certain conditions
When you wish to share your research data, you need to consider all of the above. You need to make sure you identify the rights holder(s) and get permission when relevant.
Building on other people’s work
When your work builds on other datasets, you have to ensure all rights holders have agreed to:
- The reproduction of their original work
- The sharing of their work in a modified form (eg when you merge different datasets to create a new and larger one).
At times, third-party copyright infringements prevent the publication of research outputs, such as electronic theses. Therefore, do not overlook the importance of copyright, as the future visibility of your work might be affected.
Licensing your work to enable reuse
To specify how you wish people to reuse your work, you have to license it. By choosing a licence, you can effectively tell others a number of things:
- Whether you require attribution
- What type of licence they should apply to work building upon your data
- Whether work resulting from a transformation of your data or building upon it can be shared
- Whether commercial use is permitted.
Note that, to enable digital preservation, a copyright declaration permitting format shifting is normally required.
Further reading
- University of Glasgow - Introduction to Ownership of Rights in Research Data
- University of Glasgow - Choosing a Licence for Research Data
- University of Glasgow - FAQ: Using Research Data
- University of Glasgow - Making Research Data Available
- RDA-CODATA - Legal Interoperability of Research Data: Principles and Implementation Guidelines
- University of Glasgow - Introduction to Ownership of Rights in Research Data
- University of Glasgow - Choosing a Licence for Research Data
- University of Glasgow - FAQ: Using Research Data
- University of Glasgow - Making Research Data Available
- RDA-CODATA - Legal Interoperability of Research Data: Principles and Implementation Guidelines
Licensing
Licences are essential to enable data reuse. You need a licence to clearly state what others can do with your work, whether they must cite it, and how they can share derivative work.
Bespoke and standard licences
The two main types of licence are bespoke and standard licences. We suggest you avoid bespoke licences, as they are difficult to create, although we recognise you might need them in some cases. Standard licences are usually available when depositing the data in a repository – often you will be asked to pick an option among:
Each of these has sub-options, which might be confusing if you have never heard of them. We recommend that you stick to public domain licences as far as possible. These allow the greatest reusability and place no restrictions upon the way you use data. If you are concerned about attribution, it is possible to add an optional suggestion that re-users state the origin of the data.
Getting help to choose a licence
These sites can help you to make an informed decision:
- Licence selector tool (Github)
- Choose an open source license (Github for software)
- How to license research data (pdf) (Digital Curation Centre)
The three layers of licences
When depositing data, you should consider three layers of licences:
- The legal code (ie the law): this is the traditional version of a licence, written with legal jargon and used in courts of law
- A human-readable licence: this is a version of the legal terms that laymen will understand. As a researcher, a human-readable licence will clarify what can and cannot be done with the data
- A machine-readable licence: this is the least common version of licence but a very important one. A machine-readable licence tells computers what the key freedoms and obligations are with respect to the data. Automated software, search engines and customised algorithms all benefit from machine-readable licences
When applying a licence to your data, these three layers should be in place. In some cases, it is more practical to focus on one of them and then address the others at a later stage. If possible, we recommend you avoid this, but it is certainly more desirable to have at least one of these layers in place rather than none at all.
Note that Creative Commons licences always consider all three layers mentioned above.
Further reading
Identifiers
Identifiers are a key component in scholarly communications. They allow you to cite other people’s work, be cited and document the impact of your work . Their full name is persistent identifiers (PIDs), as they ensure that an object is discoverable even if the original web address goes offline or changes location.
With the growing importance of the impact agenda, identifiers support the evaluation of researchers’ work. You can use them to provide evidence in impact tracking platforms, such as ResearchFish, KOLOLA, or Impact Tracker.
Digital object identifiers
In the case of research data, the use of digital object identifiers (DOIs) is widespread. The International DOI Foundation manages the DOI system and provides detailed documentation on it. Many applications of the DOI system exist, including:
- Crossref to manage citations in scholarly publications
- DataCite to help you locate, identify and cite research data.
The main aim of DOIs is to encourage sharing and citation. They also enable transparency and reproducibility: if a link breaks, the data is lost and research cannot be verified. As of early 2018, over 148 million DOI names have been assigned to date and over 5 billion DOI resolutions are performed every year.
In some cases, you cannot openly share your data, but you can still create a DOI. Think, for example, of cases where a researcher has to apply for ethical approval before using the data. Also, you are probably familiar with academic articles: nowadays, they all have a DOI but this doesn’t mean they are freely available.
To learn how to use DOIs in research, read linking your data to a publication.
Permalinks
Permalinks are another form of persistent identifiers. They are URLs meant to remain unchanged and are often used in blogging platforms. In research, permalinks are important when you wish to cite a webpage, which may move or go offline at any point. To address this, you may wish to create a permanent record of the pages you cite using services such as perma.cc. This service allows readers to reach a copy of the page looking exactly as it did when a researcher cited it.
Other identifiers in research
In the field of research more generally, there are other identifiers, such as ORCID . This is a persistent digital identifier defining you as a researcher and including all sorts of information on your work. Through ORCID, you can link your publications, datasets, grants and more, showcasing your experience.
Further reading
Linking your data to a publication
To link your data to a publication effectively you usually need a Digital Object Identifier (DOI). Once you have deposited the data, you will be able to get one and add a data access statement to your publication. Such a statement should explain where and how data can be obtained and, if not, why. Higher education institutions often share examples of data access statements, so check your local website or perform a web search to find out more.
Getting a DOI
Linking data to a publication is relatively simple. The key is obtaining a DOI, and you could do so by:
- Depositing data in disciplinary repositories
- Depositing data in third-party or generalist repositories
- Sharing data along with a journal publication
- Depositing data in institutional repositories
- Publishing data in a data journal.
Choosing the right option to share data
It is usually wise to go for a disciplinary repository, if any are available in your field. This gives you visibility among your peers and allows you to spot similar work that might be relevant. Otherwise, institutional or generalist repositories are a good alternative to deposit research data. Institutional repositories are most often used for articles, theses and dissertations, but they are increasingly accepting other research outputs including data. You can find appropriate options from:
Alternatively, find other options on where to deposit data.
You might find that research data is best shared alongside (one of) its accompanying publication(s). In other cases, this is mandated by academic journals. Either way, the best approach to achieve this is to deposit the data in a repository and then include its DOI in the article (eg in the form of a citation or in a formal data availability statement), so as to establish a clear link between the publication and any supporting information.
You can also share your data, accompanied by a data article, on data journals. The article would discuss the data collection and processing methods used, particularly in the case of large datasets. This is the most burdensome option, as the data would go through peer-review (while in the other options you are free to deposit what you wish). However, trust in your work will be higher, and other researchers may feel more confident when reusing the data you shared.
Finally, you could share research data on your project webpage, which we do not recommend as it would not have a DOI but just a “regular” URL. If you wish to pursue this, we suggest that you deposit the research data in a repository and only share a DOI on the project website. The risk of broken links on a dated website may be detrimental to your reputation and should be avoided.
Where should I deposit my data?
Choosing where to deposit research data is a crucial matter. It highly affects its impact, reach and audience. Making the right choice leads to increased citations and data reuse.
The million-dollar question for many researchers is where to deposit their data. This matter troubles STEM and humanities researchers alike: your choice of repository may mean a large and far-reaching impact or little to no reuse.
In linking your data to a publication, we discuss a few options to deposit data. Here, we provide further guidance on this topic.
Pathways to deposit research data
Generally speaking, we highlight three pathways to share your data:
- Using an online repository: this option involves depositing your results in a database, which can be disciplinary, institutional, or generalist. We recommend the use of disciplinary repositories for the highest visibility among your peers. Institutional and generalist repositories are suitable alternatives, as long as they provide a DOI
- Sharing data along with a publication: journals often give you the chance to share data when submitting an article. This might limit the visibility of your data (as it will be a “subset” of the article) but it will stress its links with the results. For more information on this pathway, you should refer to the policy of your journal of choice or to the guidance by the Australian National Data Service
- Preparing a data article for a data journal: if you have carried out extensive work on the data, you might wish or need to explain it. A data article gives you the chance to describe tools, methods and processes, to fully characterise your data. A data article accompanies a dataset and goes through peer review. This increases its credibility but is an extra burden for the data depositor
Choosing the right repository solution
If you decide to go down the repository route, your institutional library will be able to advise on local provision, while the following websites may help in identifying discipline-specific and generalist options:
- re3data: this website gathers details for repositories, which you can filter by subject and country
- FAIRsharing: this website gathers details for repositories, which you can filter by subject, domain and taxonomy
- SpringerNature Scientific Data’s recommendations: these include options sourced from re3data and FAIRsharing. SpringerNature appraised these repositories to ensure they meet their requirements for data access, preservation and stability
- Research Pipeline: a privately-maintained list of repositories, this includes 140 disciplinary databases. Note that this page is updated less often than the above, so we recommend you use it as a last resort
- Generalist repositories: there exist a few alternatives for these, with different affiliations and governance. You can have a look at Zenodo, Figshare, Dryad and Harvard Dataverse. Figshare is a commercial solution, while Zenodo and Harvard Dataverse are public ones
Other considerations on data deposit
If you wish to deposit software, the Software Sustainability Institute compiled a list of suitable journals split by discipline.
In all the above cases, do remember that you need appropriate metadata. When choosing where to deposit your work, you should also make sure that you make a note of the metadata standards and fields required. The Research Data Alliance compiled a list of disciplinary metadata standards. These have all been appraised and represent current practice in the fields considered.
Further reading
- EUDAT - B2FIND
- Research Data Australia - Find data for research
- The National Archives - PRONOM
- Research Data Alliance - RDA for Disciplines
- Repositive (for cancer models)
- Wolfram Data Repository
- EUDAT - B2FIND
- Research Data Australia - Find data for research
- The National Archives - PRONOM
- Research Data Alliance - RDA for Disciplines
- Repositive (for cancer models)
- Wolfram Data Repository
Discover, reuse and cite
There are two sides to research data management: you may be managing the process, or just enjoying its benefits as a consumer. This step focuses on your role as a data user and should help you understand why research data management is important.
As a data user, you can find suitable data by visiting disciplinary, generalist or institutional repositories. These normally allow you to apply filters and may offer the option to download the data. Alternatively, you might find data by following links in an article. In some cases, you may have to contact the author and/or seek permission to use a certain dataset (eg ethical approval). If this is the case, you will have to account for extra time in your project plan. Note that all of the above is enabled by good research data management practices, including documentation, metadata and the use of digital object identifiers.
When reusing someone else’s data, you need to be methodical, as there will be (or should be) terms and conditions attached to it. A solid approach is to:
- Make sure the licence applied by the author(s) is suitable for your purposes
- Respect the authors’ intellectual property
- Cite the data, if required by the licence (although we recommend always citing your sources as a good practice)
- Share any new data you might generate using the original authors’ work in accordance with the licence they chose
You might become a data re-user to verify someone else’s results. This is always permitted once you get access to a dataset and you should get in touch with authors should replication be impossible.
Data citation and metrics
Data should be cited just like academic publications. There is evidence showing how this practice yields additional citations, plus it acknowledges researchers’ efforts and allows increased transparency.
When it comes to citations, we normally think about publications. Yet citing data is becoming more common – and why shouldn’t it be? Citing data comes with a range of advantages:
- Evidence shows that, if a publication cites data, it will be cited more (see SPARC Europe - The Open Data Citation Advantage (pdf))
- Citing data acknowledges researchers’ efforts
- Linking publications to their underlying data allows transparency and reproducibility in research
- Links to data deposited online can be included in CVs and online profiles (eg ORCID)
- Deposited data contributes to impact evaluation instead of gathering dust in researchers’ desk drawers.
Equipment can be cited, too. This makes research more easily replicable, as a specific tool in an organisation can be referenced (eg via a permalink) and reused by other investigators.
Enabling data citation through research data management
Citing data is possible only when the authors deposit it in a repository and include metadata. You need their names, the publication date, a title and a DOI for a basic citation. However, there are other metadata fields that it is sometimes helpful to include, such as the data version and the resource type. Just like citing literature, you can choose between different citation styles, such as APA, Chicago, MLA and Oxford. The Digital Curation Centre collected some overarching guidance that works in most cases.
If you wish your data to be cited, we also recommend the following:
- Deposit the data in a trustworthy repository
- Use permissive licences
- Always cite your data sources
The role of metrics in research
Research data metrics (or indicators) can help you demonstrate the impact of your data sharing efforts and drive reward mechanisms. Clarivate Analytics maintains a data citation index, while altmetrics are a less formal approach to analysing the way data is perceived. Altmetrics include the number of views or downloads, social media interactions, or recommendations, and are starting to appear in several websites, such as figshare and Springer Nature’s Scientific Data.
There is a wealth of other services that allow you to measure the impact of data and its citation based on metrics. However, they are all at a relatively early stage of development and there is no agreement upon the measures used to estimate real impact.
You should be mindful that some metrics might just be a measure of the level of attention received by data. Traditional citation counts are the most highly regarded, yet uncertainty plagues the field. We recommend that you cite data as often as appropriate, to push debate forward and drive attention on these pressing matters.
Further reading
- Australian National Data Service (ANDS) - Data citation
- Force11 - Joint declaration of data citation principles
- Software Sustainability Institute - How to cite and describe software
- Digital Curation Centre - How to track the impact of research data with metrics (pdf)
- Institute for Methods Innovation - Investigating the link between research data and impact
- Nature - Making data count
- Software citation principles
- Knowledge Exchange - The value of research data – Metrics for datasets from a cultural and technical point of view (pdf)
- Australian National Data Service (ANDS) - Data citation
- Force11 - Joint declaration of data citation principles
- Software Sustainability Institute - How to cite and describe software
- Digital Curation Centre - How to track the impact of research data with metrics (pdf)
- Institute for Methods Innovation - Investigating the link between research data and impact
- Nature - Making data count
- Software citation principles
- Knowledge Exchange - The value of research data – Metrics for datasets from a cultural and technical point of view (pdf)
Training and resources for research data management
This toolkit includes a number of resources on research data management. However, due to its broad scope, the toolkit is not structured as an online course.
If that is what you are looking for, we recommend you have a look at the list below. Alternatively, you can check out the further reading gathered in the pages of this toolkit.
Courses
- Digital Humanities Registry – Courses
- Essentials 4 Data Support
- FOSTER courses
- Manage, improve and open up your research and data (Parthenos project – digital humanities)
- Research data bootcamp
- Research Data Management and Sharing
Guides
- Digital preservation – A How-To Guide for Beginners
- OpenAIRE Research Data Management Task Force – Output and Resources
- Research Data Curation Bibliography
- Research Data Management – FOSTER
- Research Data Training – CESSDA
- Sustaining Media Art
- The Open Science Training Handbook
- Toolkit of Best Practice for Research Data Management (pdf)
- Training for research data management: comparative European approaches (pdf)
- UK Data Service - research data management
Research data management videos
- Digital Preservation Coalition Webinars
- RDM Management – Drivers, Policy and Potential
- FAIR webinar series
- Open Research Data and Economic Potential
- Research Data: The Vision for the Future
- Research Data Management: The Institutional Perspective
- Reuse of Research Data: Rewards, Incentives, and Mindset
- Webinar hosted by UKDS about licensing and accessing research data
Infographics
- 23 (research data) Things
- 23 Things: Libraries for Research Data (DOI)
- Rainbow of open science practices (DOI)
Books
- Data Management for Researchers by Kristin A. Briney (2015)
- Delivering Research Data Management Services by Graham Pryor, Sarah Jones and Angus Whyte (2013)
- Exploring Research Data Management by Andrew Cox and Eddy Verbaan (2018)
- Managing Research Data by Graham Pryor (2012)
- The Data Librarian’s Handbook by Robin Rice and John Southall (2016)
Journals
- Earth System Science Data
- International Journal of Digital Curation
- Scientific Data
- The Data Science Journal
Other material
- Companion material for Managing and Sharing Research Data handbook
- VADS – Visual Arts Data Skills for Researchers
- Open science knowledge base
- Research data management (RDM) open training materials
- The Open Science Training Handbook